
My Data Story
시계열 데이터 분석 절차(2/6) - 시계열 데이터 분리 본문
1. 시계열 데이터 분석 절차(1/6) - 시계열 데이터 패턴 추출
2. 시계열 데이터 분석 절차(2/6) - 시계열 데이터 분리
시계열 데이터 분석 시 시점을 고려해 훈련셋, 검증셋, 테스트셋을 분리하는 방법에 대해 살펴보자.
3. 시계열 데이터 분석 절차(3/6) - 시계열 데이터 전처리(1)
4. 시계열 데이터 분석 절차(4/6) - 시계열 데이터 전처리(2)
5. 시계열 데이터 분석 절차(5/6) - 시계열 레퍼런스 모델 구현 및 성능 확인
6. 시계열 데이터 분석 절차(6/6) - 분석 종료 위한 잔차 진단
1. 시계열 데이터 분리 (Time Series Validation)
시계열 데이터를 준비할 때 랜덤성(set.seed)를 부여하면 안되고 시간축 유지가 핵심이다.
˙훈련셋 (Training set) : 가장 오래된 데이터
˙검증셋 (Validation set) : 그 다음 최근 데이터
˙테스트셋 (Testing set) : 가장 최신의 데이터

하지만 위 방법은 테스트셋의 시간 패턴이 반영된 상태로 모델을 평가하게 된다.
즉 테스트 셋은 미래의 데이터이기 때문에 미래의 시간 패턴 (seasonal, trend 등) 을 미리 반영한다는 것은 말이 안된다.
이럴 경우 과적합을 유발할 수 있으며 과거 정합성이 높더라도 미래의 정확성을 보장할 수 없게 된다.
따라서 시계열 데이터 분석을 할 때는 테스트 셋의 모든 시기에 대해 하나 하나 예측해 검증하거나 과거 훈련셋의 시간 패턴이 미래 테스트셋의 시간 패턴에서도 반복된다는 전제를 두고 진행해야 한다.
우선 테스트 셋의 모든 시기에 대해 하나 하나 예측해 검증하는 방법에 대해 살펴보자.
■ 1스텝 교차 검사 (One-step Ahead Cross-validation)
step1
Y(t) 를 예측하려 할 때, t-1 시점까지의 데이터를 훈련 데이터로 두고 모델 훈련을 시켜 예측한다.
step2
다음 Y(t+1)를 예측하려 할 때, t 시점까지의 데이터를 훈련 데이터로 두고 모델 훈련을 시켜 예측한다.
이때 Y(t)는 앞서 step1에서 예측한 값을 활용한다.

■ 2스텝 교차 검사 (Two-step Ahead Cross-validation)
step1
Y(t) 를 예측하려 할 때, t-2 시점까지의 데이터를 훈련 데이터로 두고 모델 훈련을 시켜 예측한다.
step2
다음 Y(t+1)를 예측하려 할 때, t-1 시점까지의 데이터를 훈련 데이터로 두고 모델 훈련을 시켜 예측한다.
step3
다음 Y(t+2)를 예측하려 할 때, t 시점까지의 데이터를 훈련 데이터로 두고 모델 훈련을 시켜 예측한다.
이때 Y(t)는 앞서 step1에서 예측한 값을 활용한다.
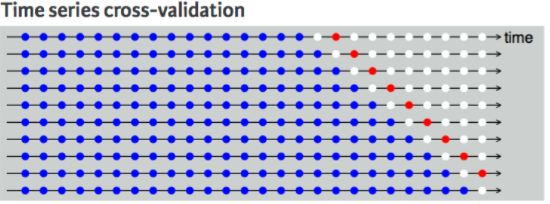
1스텝 교차 검사와 2스텝 교차 검사를 활용하여 생성한 시계열 모델은 서로 다르다.
어떤 시점에서 예측하느냐에 따라 예측 정확도와 예측 모델이 달라진다.
그래서 보통 단기적 시계열 예측 모델과 장기적 시계열 예측 모델을 각각 구현하여 분석한다.
raw_train = raw_fe[raw_fe.index < '2012-07-01']
raw_test = raw_fe[raw_fe.index >= '2012-07-01']
Y_colname = ['count']
X_remove = ['datetime', 'DateTime', 'temp_group', 'casual', 'registered']
X_colname = [x for x in raw_fe.columns if x not in Y_colname+x_remove]
x_train = raw_train[X_colname]
y_train = raw_train[Y_colname]
x_test = raw_test[X_colname]
y_test = raw_test[Y_colname]
print(x_train.describe(include='all').T)
print(x_train.info())
이론적으로 위 방법대로 진행함이 맞지만 간단하고 러프하게 '과거 훈련셋의 시간 패턴이 미래 테스트셋의 시간 패턴에서도 반복된다.'는 전제 하에 진행하는 방법에 대해 알아보자.
예를 들어 2011년 1월 ~ 2012년 12월까지의 데이터에 대해 2011년 1월 ~ 2012년 6월 데이터를 훈련셋으로 2012년 7월 ~ 2012년 12월 데이터를 테스트셋으로 나누었다. 각각의 시간 패턴을 확인해보니 차이가 큼을 확인하였다.

테스트 셋은 미래 시점의 데이터기 때문에 시간 패턴을 미리 반영해서는 안된다. (현실에서는 알 수도 없다.)
따라서 과거 훈련셋의 시간 패턴이 미래 테스트셋의 시간 패턴(seasonal, trend, moving average 등) 에서도 반복된다.'는 전제 하에 2011년 데이터의 시간 패턴을 2012년에 그대로 넣어주어 모델을 구현한다.
### Functionalize
### duplicate previous year values to next one
def feature_engineering_year_duplicated(raw, target):
raw_fe = raw.copy()
for col in target:
raw_fe.loc['2012-01-01':'2012-02-28', col] = raw.loc['2011-01-01':'2011-02-28', col].values
raw_fe.loc['2012-03-01':'2012-12-31', col] = raw.loc['2011-03-01':'2011-12-31', col].values
# 2011년 2월 29일 없지만 2012년에는 2월 29일이 존재하여 처리하는 구간
step = (raw.loc['2011-03-01 00:00:00', col] - raw.loc['2011-02-28 23:00:00', col])/25
step_value = np.arange(raw.loc['2011-02-28 23:00:00', col]+step, raw.loc['2011-03-01 00:00:00', col], step)
step_value = step_value[:24]
raw_fe.loc['2012-02-29', col] = step_value
return raw_fe
target = ['count_trend', 'count_seasonal', 'count_Day', 'count_Week', 'count_diff']
raw_fe = feature_engineering_year_duplicated(raw_fe, target)
lagged time 의 경우 직접 테스트셋 데이터에 대해, shift() 함수를 적용하여 구성한다.
shit(1) 일 경우 테스트셋의 첫번째 데이터는 NaN 이므로 이를 채워주도록 한다.
### modify lagged values of X_test
def feature_engineering_lag_modified(Y_test, X_test, target):
X_test_lm = X_test.copy()
for col in target:
X_test_lm[col] = Y_test.shift(1).values
X_test_lm[col].fillna(method='bfill', inplace=True)
X_test_lm[col] = Y_test.shift(2).values
X_test_lm[col].fillna(method='bfill', inplace=True)
return X_test_lm
# target = ['count_lag1', 'count_lag2']
# X_test_fe = feature_engineering_lag_modified(Y_test_fe, X_test_fe, target)'Time Series Analysis > 1. 시계열 분석 절차' 카테고리의 다른 글
| 시계열 데이터 분석 절차(6/6) - 분석 종료 위한 잔차 진단 (0) | 2021.11.14 |
|---|---|
| 시계열 데이터 분석 절차(5/6) - 시계열 레퍼런스 모델 구현 및 성능 확인 (0) | 2021.11.14 |
| 시계열 데이터 분석 절차(4/6) - 시계열 데이터 전처리(2) (0) | 2021.11.14 |
| 시계열 데이터 분석 절차(3/6) - 시계열 데이터 전처리(1) (0) | 2021.11.14 |
| 시계열 데이터 분석 절차(1/6) - 시계열 데이터 패턴 추출 (0) | 2021.11.09 |



