
My Data Story
[개요] 머신러닝의 주요 도전 과제 본문
◈ '머신러닝 개요' 목차 ◈
2. 머신러닝의 주요 도전 과제
머신러닝 프로젝트 진행 시 데이터, 알고리즘, 검증 측면에서 발생할 수 있는 이슈에 대해 살펴보자.
1. 나쁜 데이터
1.1 충분하지 않은 양의 훈련 데이터
복잡한 문제에서 알고리즘보다 데이터 양이 더 중요하지만
보통은 작거나 중간 규모의 데이터셋이 여전히 흔하고 훈련 데이터를 추가로 모으기 쉽지 않기에
아직은 알고리즘을 무시하지 말아야 한다.
1.2 대표성 없는 훈련 데이터
샘플이 작으면 샘플 잡음 sampling noise (우연에 의한 대표성 없는 데이터)이 생기고
샘플이 크더라도 표본 추출의 방법이 잘못되면 대표성을 띄지 못 할 수 있다.
즉 샘플링 편향 sampling bias 가 발생할 수 있다.
1.3 낮은 품질의 데이터
훈련 데이터에 에러 error, 이상치 outlier, 잡음 noise 등이 가득하다면
머신 러닝 시스템이 내재된 패턴을 찾기 어려줘 작동하지 않는다.
따라서, 훈련 데이터 정제에 시간을 투자할 가치가 있다.
1.4 관련 없는 특성
- 특성 선택 : 가지고 있는 특성 중 가장 유용한 특성을 선택
- 특성 추출 : 특성을 결합하여 더 유용한 특성을 생성 ex. 차원 축소 알고리즘
- 새로운 데이터를 수집하여 새로운 특성 생성
2. 나쁜 알고리즘
2.1 훈련 데이터 과대 적합
복잡한 모델은 데이터에서 미묘한 차이를 감지할 수 있지만,
훈련 세트에 잡음이 많거나 데이터 셋 크기가 너무 작으면 샘플링 잡음이 발생하여 잡음이 섞인 패턴을 감지하게 된다.
과대 적합은 훈련 데이터에 있는 잡음의 양에 비해 모델이 너무 복잡할 때 발생한다.
과대 적합 해결 방법
- 파라미터가 적은 모델 선택
- 훈련 데이터에 있는 특성 수 줄이기
- 모델에 제약을 가하여 단순화 시키기(규제)
- 훈련 데이터 더 모으기
- 훈련 데이터의 잡음 줄이기 => 오류 데이터 수정하고 이상치 제거
※ 모델 파라미터 vs 하이퍼파라미터
하이퍼파라미터는 학습 알고리즘의 파라미터로, 훈련 전에 미리 지정되어 훈련하는 동안 상수로 존재한다.
모델의 파라미터는 데이터를 가장 잘 표현할 수 있는 알고리즘의 계수 값이다.
ex. 회귀모델의 회귀 계수
2.2 훈련 데이터의 과소 적합
모델이 너무 단순해서 데이터의 내재된 구조를 학습하지 못할 때 발생한다.
과소 적합 해결 방법
- 모델의 파라미터가 더 많은 강력한 모델 선택
- 학습 알고리즘에 더 좋은 특성을 제공한다. (특성 공학)
- 모델의 제약을 줄인다. (규제 파라미터를 줄인다.)
3. 테스트와 검증
모델을 운영 반영하기 전에, 얼마나 일반화되는 지 검증하는 단계가 필요하다.
즉 새로운 샘플에 얼마나 잘 작동하는 지 파악해야 한다.
보통 데이터의 80%를 훈련 세트로 20%를 테스트 세트로 나누어
테스트 세트에서 새로운 샘플의 오류 비율 즉 일반화 오차를 추정하여 모델을 평가한다.
3.1 하이퍼파라미터 튜닝과 모델 선택
모델 선택 시, 후보 모델을 선택할 때와 선택된 모델의 하이퍼파라미터를 결정하기 위해 테스트 세트를 여러 번 사용하면 실제 모델의 성능이 생각보다 좋지 않다. 이는 모델과 하이퍼파라미터가 테스트 세트에 최적화된 모델을 생성한 것이기 때문이다.
홀드 아웃 검증과 교차 검증을 통해 해결할 수 있다.
(1) 홀드 아웃 검증
훈련 세트의 일부를 떼어내어 후보 모델 평가하고 가장 좋은 모델을 선택한다. 떼어낸 홀드 아웃 세트를 검증 세트라 한다.

step1
전체 훈련 세트에서 검증 세트 제외한 나머지 데이터로, 다양한 파라미터의 값을 가진 여러 모델을 훈련한다.
step2
검증 세트로 가장 높은 성능을 내는 모델 및 하이퍼파라미터 선택
step3
전체 훈련 세트에서 다시 훈련하여 최종 모델 생성
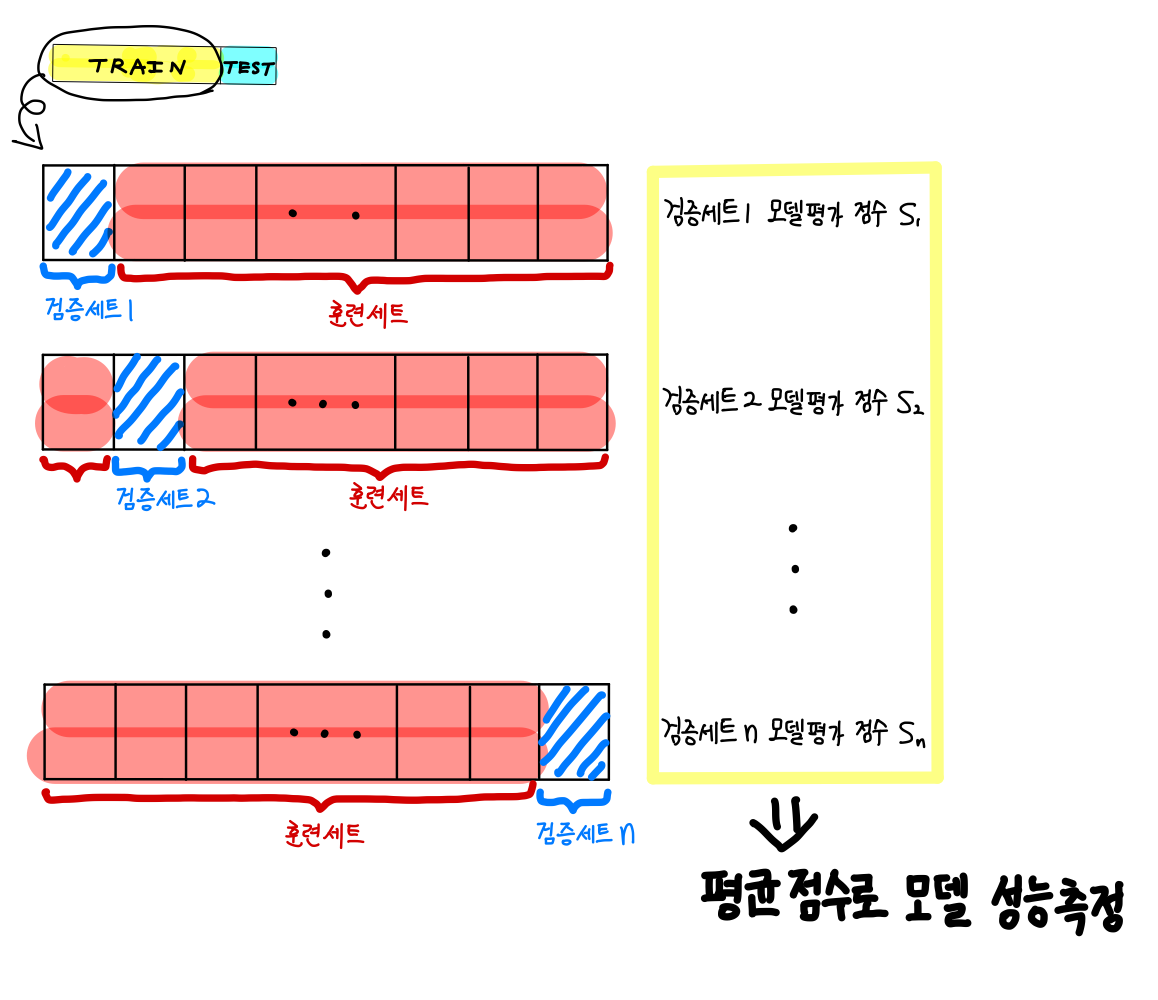
(2) 교차 검증
홀드 아웃 검증은 잘 작동하지만, 검증 세트가 너무 작으면 모델이 정확하게 평가되지 않고 검증 세트가 너무 크면 훈련 세트가 적어 제대로 훈련되지 않는다. 이를 보완한 최적의 방법이 교차 검증이다.
교차 검증은 작은 검증 세트를 여러 개 사용하여 반복한다. 검증 세트마다 나머지 데이터에서 훈련한 모델을 검증 세트에서 평가한다. 모든 검증 세트의 모델 평가를 평균하면 훨씬 정확한 성능을 측정할 수 있다.
(3) 데이터 불일치
검증 세트와 테스트 세트가 실전에서 기대하는 데이터를 가장 잘 대표해야 한다. 따라서 검증 세트와 테스트 세트에 대표 데이터를 배타적으로 포함되도록 한다.
훈련된 모델이 검증 세트에서 성능이 안 나올 때 '모델이 훈련 세트에 과대 적합된 것인지?', '훈련 세트와 검증 세트 간의 데이터 불일치 때문인지?' 알기 어렵다. 이럴 경우 훈련-개발 세트를 사용하면 도움이 된다. 훈련-개발 세트는 훈련에 사용된 데이터 일부를 가져와 또 다른 세트를 생성한다.

- 검증 세트 성능 : 나쁨, 훈련 세트 성능 : 좋음, 훈련-개발 세트 성능 : 나쁨
=> 훈련 세트에 과적합된 모델 - 검증 세트 성능 : 나쁨, 훈련 세트 성능 : 좋음, 훈련-개발 세트 성능 : 좋음
=> 훈련 세트와 검증+테스트 세트 사이의 데이터 불일치 존재
=> 훈련 세트 보정 필요
'Machine Learning > 1. 머신러닝 프로젝트 절차' 카테고리의 다른 글
| [개요] 머신러닝 프로젝트 절차(4) - 머신러닝 알고리즘을 위한 데이터 준비 (0) | 2021.08.12 |
|---|---|
| [개요] 머신러닝 프로젝트 절차(3) - 데이터 이해를 위한 탐색 ... 수정중 (0) | 2021.08.12 |
| [개요] 머신러닝 프로젝트 절차 (2) - 데이터 샘플링 및 훈련/테스트 세트 만들기 (0) | 2021.08.12 |
| [개요] 머신러닝 프로젝트 절차(1) - 큰 그림 보기 (0) | 2021.08.12 |
| [개요] 머신러닝 시스템의 종류 (0) | 2021.08.12 |


