
My Data Story
[군집] 유사도 전파 본문
◈ '군집' 목차 ◈
7. 유사도 전파
유사도 전파 군집 알고리즘에 대해 알아보자.
1. 유사도 전파
이 알고리즘은 투표 방식을 사용한다.
샘플은 자신을 대표할 수 있는 비슷한 샘플에 투표한다.
만약 스스로가 자기 자신에게 투표하게 되면 클러스터의 중심이 된다.
알고리즘이 수렴하면 각 대표와 투표한 샘플이 하나의 클러스터로 감지할 수 있다.
유사도 전파는 클러스터의 갯수를 미리 선정하지 않아도 된다는 점에서 가장 큰 장점이 있다.
유사도 전파는 크기가 다른 여러 개의 클러스터를 감지할 수 있지만,
알고리즘의 복잡도는 O(m^2) 이라 대규모 데이터 셋에는 적합하지 않다.
아래와 같은 데이터가 존재한다고 할 때, 유사도 전파 알고리즘 과정은 다음과 같다.
| feature1 | feature2 | feature3 | feature4 | feature5 | |
| P1 | 3 | 4 | 3 | 2 | 1 |
| P2 | 4 | 3 | 5 | 1 | 1 |
| P3 | 3 | 5 | 3 | 3 | 2 |
| P4 | 1 | 1 | 3 | 2 | 3 |
| P5 | 1 | 1 | 3 | 2 | 3 |
step1
모든 데이터 간의 유사성을 측정하여, 유사도 행렬(Similarity Matrix)을 생성한다.
아래 그림은 데이터 P3 에 대한 유사도 측정 방식을 도식화한 그림이다.

모든 데이터에 대해 유사도를 측정하여 유사도 행렬을 생성하면 다음과 같다.
| P1 | P2 | P3 | P4 | P5 | |
| P1 | -22 | -7 | -6 | -12 | -17 |
| P2 | -7 | -22 | -17 | -17 | -22 |
| P3 | -6 | -17 | -22 | -18 | -21 |
| P4 | -12 | -17 | -18 | -22 | -3 |
| P5 | -17 | -22 | -21 | -3 | -22 |
step2
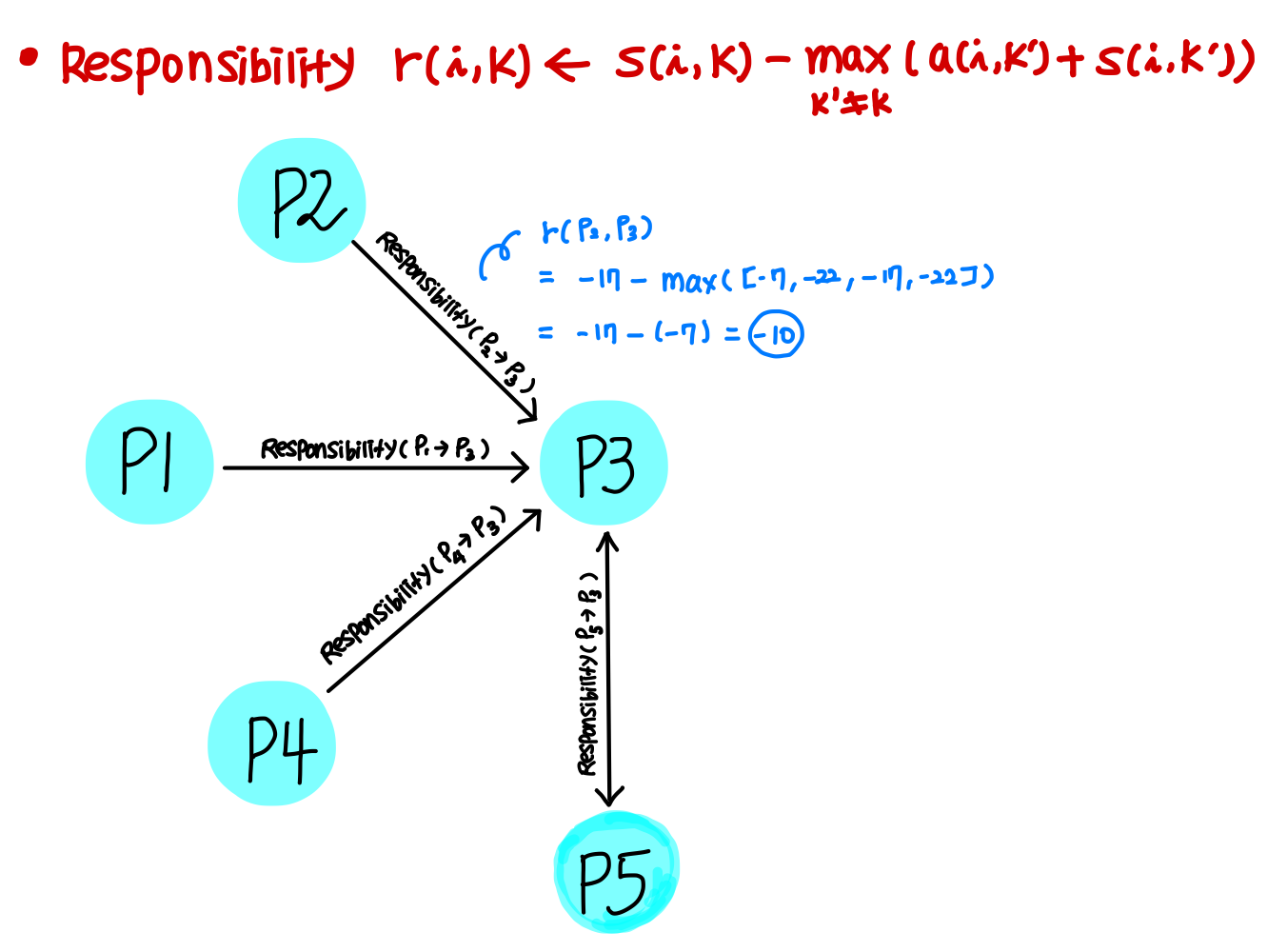
측정한 유사성 S(i,k) 바탕으로 데이터 i의 대표 데이터가 k가 되어야 하는 책임 크기를 측정한다.
아래 그림은 데이터 P3에 대한 다른 데이터들의 책임을 도식화한 것이다.
이와 동일하게 모든 데이터에 대해 책임 크기를 측정하여 Responsibility Matrix를 생성한다.
이때 availbility 에 해당하는 a(i,k) 의 초기값은 0 이다.
모든 데이터에 대해 Responsibility Matrix 를 그리면 다음과 같다.
| P1 | P2 | P3 | P4 | P5 | |
| P1 | -16 | -1 | 1 | -6 | -11 |
| P2 | 10 | -15 | -10 | -10 | -15 |
| P3 | 11 | -11 | -16 | -12 | -15 |
| P4 | -9 | -14 | -15 | -19 | 9 |
| P5 | -14 | -19 | -18 | 14 | -19 |
step3
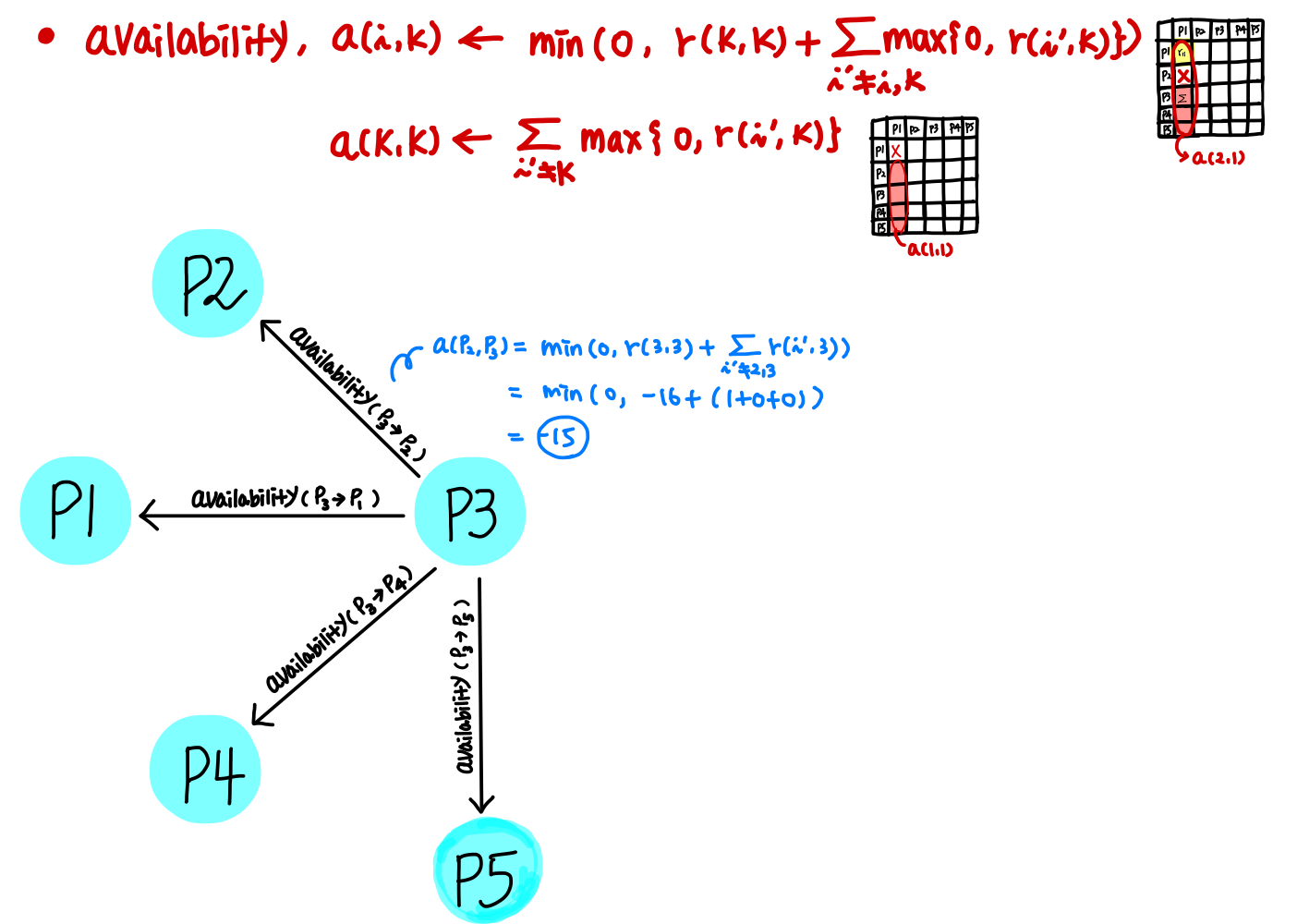
측정한 Responsibility Matrix 바탕으로 Availability Matrix 를 구한다.
Availability Matrix 생성 시, 대각선 요소와 그 외 요소를 구하는 방법이 다르다.
아래 그림은 데이터 P3에 대한 Availabilty 를 도식화한 그림이다.
모든 데이터에 대해 Availability 를 측정하여 Availability Matrix 를 생성하면 다음과 같다.
| P1 | P2 | P3 | P4 | P5 | |
| P1 | 21 | -15 | -16 | -5 | -10 |
| P2 | -5 | 0 | -15 | -5 | -10 |
| P3 | -6 | -15 | 1 | -5 | -10 |
| P4 | 0 | -15 | -15 | 14 | -19 |
| P5 | 0 | -15 | -15 | -19 | 9 |
step4
r(i,k) 와 a(i,k) 가 수렴할 때까지 step1 ~ step3 과정 반복한다.
r(i,k) 와 a(i,k) 가 수렴할 경우,
Responsibility Matrix 와 Availability Matrix 를 합하여 기준 매트릭스를 생성하고
각 데이터 행(row) 에 대해 가장 큰 값을 갖는 데이터 열(Column) 을 대표 샘플로 선정한다.
동일한 대표 샘플을 갖는 데이터끼리 클러스터링지어주면된다.
아래 그림은 데이터 P3에 대한 기준 매트릭스를 도식화한 그림이다.

모든 데이터에 대해 기준 매트릭스를 생성하면 다음과 같다.
| P1 | P2 | P3 | P4 | P5 | |
| P1 | 5 | -16 | -15 | -11 | -21 |
| P2 | 5 | -15 | -25 | -15 | -25 |
| P3 | 5 | -26 | -15 | -17 | -25 |
| P4 | -9 | -29 | -30 | -5 | -10 |
| P5 | -14 | -34 | -33 | -5 | -10 |
2. AffinityPropagation 클래스
사이킷런에서 AffinityPropagation 클래스를 통해 유사도 전파 군집을 구현할 수 있다.
Affinity Propagation 클래스의 몇 가지 매개 변수를 살펴보자
˙damping : 새로 들어오는 값에 대해 현재 값을 유지하는 정도로 0.5가 디폴트 값
˙convergence_iter : 수렴으로 간주하기 위한 반복 횟수(X번 동안 r(i,k) 와 a(i,k) 변화 없으면 수렴으로 간주)
˙preference : 클러스터 내 요소 갯수에 영향을 준다.
˙affinity : 유사도 측정 시 사용할 지표
from sklearn.cluster import AffinityPropagation
clustering = AffinityPropagation(random_state=5)
clustering.fit(X)
clustering.predict(X_new)
print(clustering.labels_)
print(clustering.cluster_centers_)
▶ AffinityPropagation클래스 구현에 대해 더 자세히 알고 싶다면 >> 참고 URL - AffinityPropagation
'Machine Learning > 3. 비지도 학습 알고리즘' 카테고리의 다른 글
| [군집] 가우시안 혼합 모델 (0) | 2023.08.19 |
|---|---|
| [군집] 스펙트럼 군집 (0) | 2023.08.19 |
| [군집] BIRCH (0) | 2023.08.19 |
| [군집] 평균-이동 (0) | 2023.08.19 |
| [군집] 병합군집 (0) | 2023.08.19 |


