
My Data Story
[모델 알고리즘][앙상블 학습] XGBoost 본문
◈ '앙상블 학습' 목차 ◈
5. XGBoost
최적화된 그레이디언트 부스팅 구현 패키지 XGBoost 에 대해 살펴보자.
1. XGBoost 란?
XGBoost는 최적화된 그레이디언트 부스팅 구현으로 유명하다.
XGBoost의 목적 함수는 손실 함수에 규제항을 추가하여 과적합을 줄일 수 있도록 한다.
이때 손실 함수는 과제 종류에 따라 달라진다.
회귀 문제 시 Squared Error 를 활용하고, 이진 분류 문제 시 Logisitic 손실 함수를 활용하고, 다중 분류 문제 시 Softmax 손실 함수를 활용한다. 그 밖에도 활용 가능한 손실 함수 종류가 다양하다.

XGBoost는 순차적으로 이전 학습기에서 예측한 값 바탕으로 목적 함수를 최소화할 수 있는 방향으로 새로운 약한 학습기가 생성된다. 이를 수식으로 표현하면 다음과 같다.

연속적으로 t개의 약한 학습기를 생성하였다고 할 때, t개의 학습기 바탕으로 예측한 값은 다음과 같다.
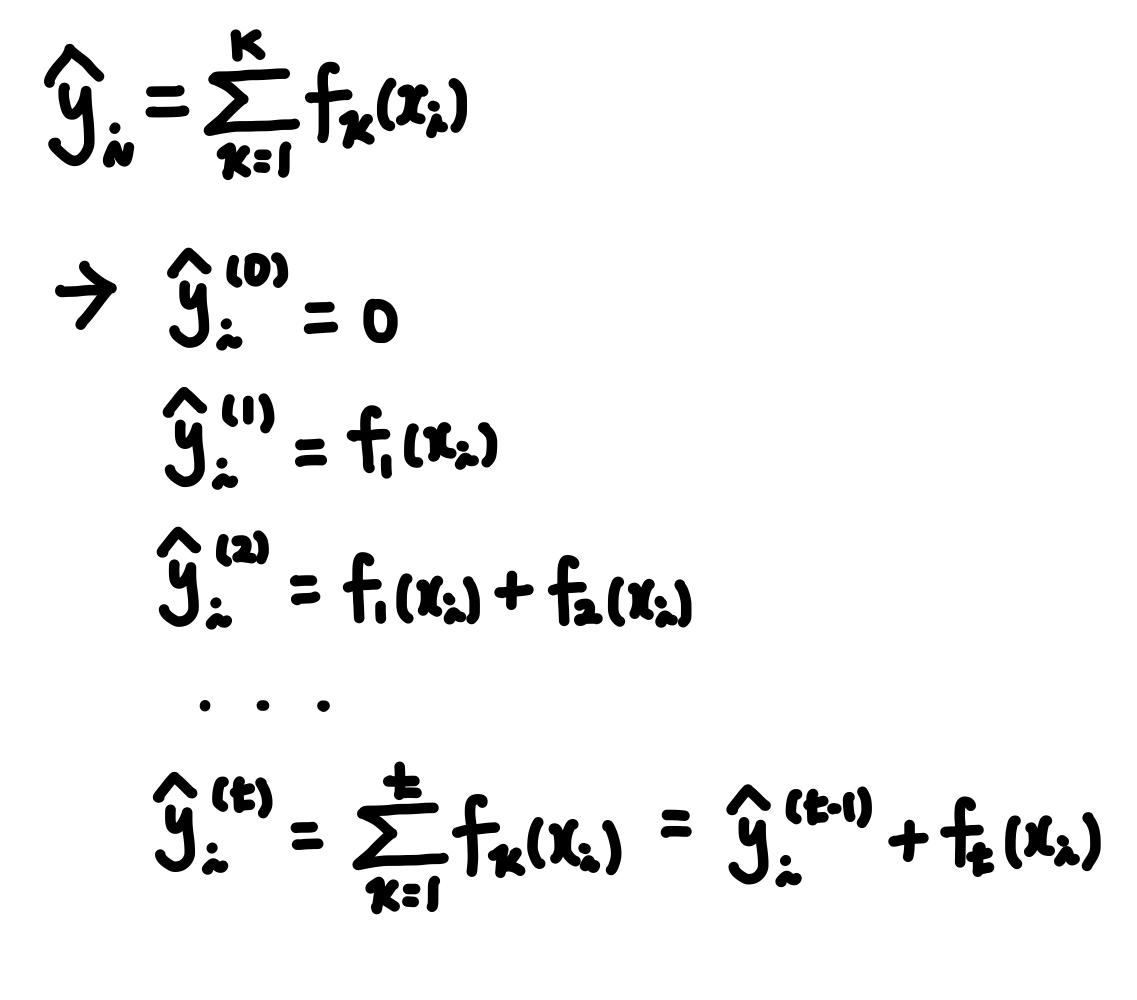
t번째 학습기에서의 예측값은 샘플이 할당된 리프를 바탕으로 계산된 Score 라고 할 수 있다.

아래 예시를 살펴보자.
샘플 X={x1, x2, x3, x4, x5} 에 대해 2개의 약한 학습기를 생성하였을 때, 각 샘플에 대한 최종 예측값은 다음과 같다.

※ 실제 Score를 계산하는 수식 과정이 궁금하다면 다음 URL을 참고하도록 하자. => 참고 URL1 , 참고 URL2
2. XGBoost 특징
XGBoost는 지도 학습 영역, 분류와 회귀에서 뛰어나 예측 성능을 발휘하여 많은 Kaggle 문제에서 우승 모델로 사용된다.
XGBoost는 병렬처리 가능하도록 변형하여 GBM에 비해 수행 속도가 빠르다.
XGBoost의 목적 함수를 살펴보면 규제항이 존재하여 과적합에 강한 내구성을 가질 수 있습니다.
다른 GBM과 마찬가지로 XGBoost도 매개 변수 max_depth로 모델의 Complexity를 조정하기도 하지만,
내부적으로 가지치기(tree pruning) 으로 더 이상 Gain(이득)이 없는 분할들을 가지치기하여 모델의 Complexity를 조정한다.
뿐만 아니라 XGBoost 내부적으로 교차 검증을 수행하여 최적화된 반복 수행 횟수를 가질 수 있다.
이외에도 결손값을 자체적으로 처리할 수 있는 기능도 있다.
3. XGBoost 구현
3.1 하이퍼파라미터
XGBoost 구현 시 주로 사용하는 파라미터에 대해 살펴보도록 하자.
■ General Parameters
˙ booster : default 는 gbtree로 gbtree, gblinear, dart 등 설정 가능
■ Parameters for Tree Booster
˙ learning_rate : 학습률과 같은 파라미터로 보통 0.01 ~ 0.2 사이의 값을 사용한다. (default =0.333)
˙max_depth : 트리 모델 생성 시 과적합 방지로 사용하는 최대 깊이로 3 ~ 10 사이의 값을 사용한다. (default =6)
˙min_child_weight : 트리의 리프 노드 분기를 위한 리프 내 instance 의 최소 비율 값이다. (default =0)
˙gamma : 트리의 리프 노드 분기를 위한 최소 손실 감소 값으로 값이 클 수록 과적합 방지 효과가 있다. (default =0)
˙sub_sample : 트리 생성 시 데이터 샘플링하는 비율을 정해준다. 보통 0.5 ~ 1 사이의 값을 사용한다. (default =1)
˙colsample_bytree : 트리 생성시 사용할 feature를 임의로 샘플링하는 데 사용한다. (default =1)
˙reg_lambda : L2 규제 적용 값으로 값이 클 수록 과적합 방지 효과가 있다. (default =1)
˙reg_alpha : L1 규제 적용 값으로 값이 클 수록 과적합 방지 효과가 있다. (default =0)
■ Learning Task Parameters
˙objective : 약한 학습기 생성을 위해 최적화 시켜야 하는 손실 함수를 정의해준다.
˙eval_metric : 검증에 사용되는 함수를 정해준다. 분류 문제 시 error 회귀 문제 시 rmse 가 default 값이다.
※ 그 외의 파라미터에 대해 궁금하다면 다음 URL을 참고하도록 하자. => 참고 URL
3.2 하이퍼파라미터 튜닝
사이킷런에서 하이퍼파라미터 기본 값으로 xgboost 를 구현하면 다음과 같다.
import xgboost
xgb_reg = xgboost.XGBRegressor()
xgb_reg.fit(X_train, y_train)
y_pred = xgb_reg.predict(X_val)
그렇다면 XGBoost 하이퍼파라미터 튜닝 시 어떻게 접근하면 좋을까?
물론 컴퓨팅 성능이 뒷받침된다면, 모든 파라미터에 대해 한 번에 GridSearch 진행하는 것이 좋다.
하지만 컴퓨팅 성능이 그렇지 못하다면 다음과 같은 접근을 추천한다.
step1
우선 learning_rate과 n_estimators 를 고정한다.
learning_rate 은 0.1 정도로 어느 정도 크게 설정하고, n_estimators 는 1000 으로 둔다.
(learning_rate 과 n_estimators 는 최종적으로 다시 튜닝을 진행할 것이기에, 초기 고정된 값에 크게 신경 쓰지 않아도 된다.)
step2
주요 하이퍼파라미터에 대해 권장되는 값들을 설정하여 XGBoost 모델을 생성한다.
˙ max_depth : 5 (3~10 사이의 값을 권장한다.)
˙ min_child_weight : 1 (너무 작은 값을 설정하면 imbalanced class 문제 발생하기 쉽고, 리프 노드의 크기가 너무 작아진다.)
˙ gamma : 0 (0.1 ~ 0.2 정도로 작은 값으로 시작하길 권장한다.)
˙ subsample, colsample_bytree : 0.8 (0.5 ~ 0.9 사이의 값을 권장하는데, 시작할 때 흔히들 0.8 을 사용한다.)
import xgboost
xgb_reg = xgboost.XGBRegressor(learning_rate = 0.1,
n_estimators = 1000,
max_depth = 5,
min_child_weight = 1,
gamma = 0,
subsample = 0.8,
colsample_bytree = 0.8
)
xgb_reg.fit(X_train, y_train)
y_pred = xgb_reg.predict(X_val)
이렇게 XGBoost 모델을 생성하면 XGBoost 내부적으로 교차 검증을 실행하여 최적의 estimators 수를 알려준다. 앞으로 n_estimators = 최적 estimators 수 로 설정하여 XGBoost 학습시킨다.
step3
모델 결과에 가장 큰 영향을 주는 max_depth와 min_child_weight 에 대해 GridSearch 진행한다. 이때 max_depth 와 min_child_weight 를 제외한 나머지 하이퍼파라미터는 위의 값으로 설정한다.
from sklearn.model_selection import GridSearchCV
param_test1 = {
'max_depth' : range(3,10,2),
'min_child_weight' : range(1,6,2)
}
grid_search1 = GridSearchCV(estimator = xgboost.XGBRegressor(learning_rate = 0.1,
n_estimators = 145,
gamma = 0,
subsample = 0.8,
colsample_bytree = 0.8),
param_grid = param_test1,
scoring = 'rmse',
cv=5)
grid_search1.fit(X_train, y_train)
grid_search1.gird_scores_, grid_search1.best_params_, grid_search1.best_score_
step4
앞서 선정된 min_child_weight 과 max_depth 최적값 바탕으로 gamma 에 대해 GridSearch 진행한다.
step5
앞서 선정된 gamma 최적값 바탕으로 subsamepl 과 colsample_bytree 에 대해 GridSearch 진행한다.
step6
이제 Over Fitting 된 모델에 대해 규제를 적용하기 reg_alpha 에 대해 GridSearch 진행한다.
step7
주요 하이퍼파라미터에 대한 튜닝이 모두 완료되면, 마지막으로 해당 최적값 바탕으로 learning_rate 에 대해 GridSearch 진행한다.
※ XGBoost 파라미터 튜닝 참고 문헌 - 참고 문헌 URL
3.3 조기 종료
XGBoost 는 자동 조기 종료와 같은 여러 좋은 기능도 제공한다.
xgb_reg = xgboost.XGBRegressor()
xgb_reg.fit(X_train, y_train,
eval_set=[X_val, y_val], early_stopping_rounds=2)
y_pred = xgb_reg.predict(X_val)
'Machine Learning > 2. 지도 학습 알고리즘' 카테고리의 다른 글
| [모델 알고리즘][앙상블 학습] 스태킹 (0) | 2021.08.13 |
|---|---|
| [모델 알고리즘][앙상블 학습] 그레이디언트 부스팅 (0) | 2021.08.13 |
| [모델 알고리즘][앙상블 학습] 에이다부스트 (0) | 2021.08.13 |
| [모델 알고리즘][앙상블 학습] 랜덤포레스트 (0) | 2021.08.13 |
| [모델 알고리즘][앙상블 학습] 배깅, 페이스팅 (0) | 2021.08.13 |



