
My Data Story
[모델 알고리즘][앙상블 학습] 스태킹 본문
728x90
◈ '앙상블 학습' 목차 ◈
6. 스태킹
스태킹 컨셉에 대해 이해해보자.
1. 스태킹
'앙상블에 속하는 모든 예측기의 예측을 취합할 때 간단한 함수 대신에 취합하는 모델을 생성할 수 없을까?' 라는 기본 아이디어에서 출발한다. 하위 예측기 각각의 값을 취합하여 최종 결과를 예측하는 마지막 예측기를 블렌더 또는 메타 학습기라고 한다.

블렌더를 학습시키는 일반적인 방법은 홀드 아웃 세트를 사용한다.
step1
훈련 세트를 두 개의 서브셋으로 나눈다.
첫 번째 layer에 3개의 예측기가 있다 할 때, 첫 번째 subset은 첫 번째 layer의 예측기를 훈련시키기 위해 사용된다.
step2
첫 번째 layer의 예측기로 두 번째 subset (홀드 아웃 세트) 에 대한 예측을 만든다.
step3
두 번째 subset에 대한 3개의 예측값을 입력 특성으로 하고, 두 번째 subset 의 target 값을 그대로 사용하여 블렌더 훈련 시킨다.

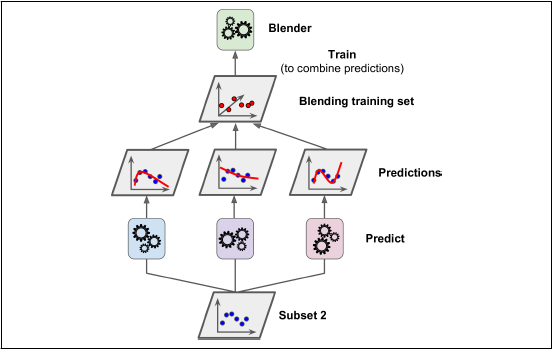
즉 첫번째 layer 의 예측값을 바탕으로 최종 target 값을 예측하는 방식이다.
이런 방식의 블렌더를 여러 개 훈련시키는 것도 가능하다.
여러 개의 블렌더를 추가할 때 마다 layer 를 추가해주고, layer 수 만큼 훈련 세트를 subset 으로 나눠준다.
'Machine Learning > 2. 지도 학습 알고리즘' 카테고리의 다른 글
| [모델 알고리즘][앙상블 학습] XGBoost (0) | 2021.09.16 |
|---|---|
| [모델 알고리즘][앙상블 학습] 그레이디언트 부스팅 (0) | 2021.08.13 |
| [모델 알고리즘][앙상블 학습] 에이다부스트 (0) | 2021.08.13 |
| [모델 알고리즘][앙상블 학습] 랜덤포레스트 (0) | 2021.08.13 |
| [모델 알고리즘][앙상블 학습] 배깅, 페이스팅 (0) | 2021.08.13 |
'Machine Learning/2. 지도 학습 알고리즘' Related Articles
more



