
My Data Story
[모델 알고리즘] 서포트 벡터 머신 - 선형 SVM 분류 본문
◈ '서포프 벡터 머신' 목차 ◈
1. 선형 SVM 분류
SVM 분류 알고리즘에 대해 이해하고, 사이킷런을 통해 선형 SVM 분류 모델을 구현하는 방법을 살펴보자.
SVM은 매우 강력하고 선형이나 비선형 분류, 회귀, 이상치 탐색에도 사용할 수 있는 다목적 머신러닝 모델이다.
SVM은 특히 복잡한 분류 문제에 잘 들어 맞으며 작거나 중간 크기의 데이터 셋에 적합하다.
1. SVM 분류 알고리즘
svm 분류기는 클래스 사이에 가장 넓은 도로를 찾는 것으로 생각할 수 있다.
그래서 라지 마진 분류 Large Margin Classification 이라고도 한다.
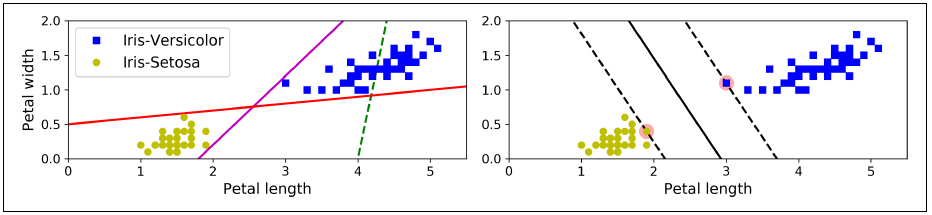
도로 바깥쪽에 훈련 샘플을 추가해도 결정 경계에는 전혀 영향을 미치지 않는다.
도로 경계에 위치한 샘플에 의해 전적으로 결정된다.
이런 샘플을 서포트 벡터 support vector 라고 한다.
SVM 은 특성의 스케일에 민감하다.
StandardScaler를 사용하여 특성의 스케일을 조정하면 결정 경계가 훨씬 좋아질 것이다.
SVM 은 이상치에도 민감하다.
반드시 이상치를 제거한 후 모델 구현한다.
1.1 하드 마진 분류 Hard Margin Classification
하드 마진 분류는 모든 샘플이 도로 바깥쪽으로 올바르게 분류하는 모델이다.
하드 마진 분류에는 2가지 문제점이 있다.
첫 번째, 데이터가 선형적으로 구분될 수 있어야 제대로 동작한다.
두 번째, 이상치에 민감하다.

1.2 소프트 마진 분류 Soft Margin Classification
소프트 마진 분류는 도로의 폭을 가능한 넓게 유지하는 것과 마진 오류 사이에 적절한 균형을 잡는 유연한 모델이다.
(cf. 마진 오류 - 샘플이 도로 중간이나 반대쪽에 있는 경우)
사이킷런 SVM 모델 생성 시, 하이퍼파라미터 C값을 조정하여 모델 생성 가능하다.
C값을 높이면, 마진 오류는 적지만 도로 폭이 좁아지면서 과대 적합될 수 있다.
C값을 낮추면, 마진 오류는 비교적 크지만 도로 폭이 넓어지면서 일반화 잘 될 수 있다.
만약 모델이 과대적합이라면, C값을 줄여 모델을 규제할 수 있다.
(SVM의 매개변수 C값은 LogisticRegression의 매개변수 C와 비슷하다.)

2. 선형 SVM 분류 모델 구현
사이킷런을 통해 LinearSVC, SVC, SGDClassifier 3가지 방법으로 선형 SVM 분류 모델을 구현하는 방법에 대해 알아보자.
2.1 LinearSVC
LinearSVC 는 규제에 편향을 포함시킨다. (일반적으로 가중치에 대해서만 규제 포함한다.)
그래서 StandardSclaer 사용하여 훈련세트에서 평균 빼서 중앙에 맞춰야 한다.
loss 는 hinge 를 지정해야 한다.
마지막으로 훈련 샘플보다 특성이 많지 않다면, 성능을 높이기 위해 dual 매개 변수를 False로 지정한다.
import numpy as np
from sklearn import datasets
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris['data'][:,(2,3)]
y = (iris['target'] == 2)
#(방법1) LinearSVC
svm_clf = Pipeline([
('scaler', StandardScaler()),
('LinearSVC', LinearSVC(C=1, loss='hinge'))
])
svm_clf.fit(X, y)
2.2 SVC
from sklearn.svm import SVC
#(방법2) SVC
svc_clf = SVC(kernel='linear', C=1)
svc_clf.fit(X, y)
2.3 SGDClassifier
SGDClassifier 는 LinearSVC 분류기를 훈련시키기 위해 확률적 경사 하강법을 적용한 것이다.
LinearSVC 만큼 빠르게 수렴하지는 않지만,
데이터 셋이 아주 커서 메모리에 적재할 수 없거나 (외부 메모리 훈련),
온라인 학습으로 분류 문제를 다룰 때 유용하다.
from sklearn.linear_model import SGDClassifier
#(방법3) SGDClassifier
#m은 샘플 수, C는 규제 강도 값으로 입력
sgd_clf = SGDClassifier(loss='hinge', alpha=1/(m*C)
sgd_clf.fit(X,y)
※ LinearSVC vs SVC
| LinearSVC | SVC |
| predict_prob() 제공 X | 매개 변수 probablity = True 선정하면 predic_proba() 제공 |
| liblinear 라이브러리 사용 | libsvm 라이브러리 사용 |
| OvR 방식 채택 | OvO 방식 채택 |
| 선형 모델만 생성 가능 | 선형, 비선형 모델 생성 가능 |
| squared_hinge 손실 함수 사용 | hinge 손실 함수 사용 |
'Machine Learning > 2. 지도 학습 알고리즘' 카테고리의 다른 글
| [모델 알고리즘] 서포트 벡터 머신 - SVM 회귀 (0) | 2021.08.09 |
|---|---|
| [모델 알고리즘] 서포트 벡터 머신 - 비선형 SVM 분류 (0) | 2021.08.09 |
| [분류] K 최근접 이웃(KNN) (0) | 2021.08.09 |
| [분류] 모델 평가 (0) | 2021.08.07 |
| [분류] 다중 레이블 분류, 다중 출력 분류 (0) | 2021.08.06 |



