
My Data Story
[개요] 머신러닝 프로젝트 절차 (2) - 데이터 샘플링 및 훈련/테스트 세트 만들기 본문
[개요] 머신러닝 프로젝트 절차 (2) - 데이터 샘플링 및 훈련/테스트 세트 만들기
Hwasss 2021. 8. 12. 14:38◈ '머신러닝 프로젝트 절차' 목차 ◈
2. 머신러닝 프로젝트 절차(2) - 데이터 샘플링 및 훈련/테스트 세트 만들기
본격적인 데이터 분석에 앞서, 데이터 구조를 살펴보고 데이터에 맞는 샘플링하여 훈련 세트와 테스트 세트를 분리한다.
3. 머신러닝 프로젝트 절차(3) - 데이터 이해를 위한 탐색
4. 머신러닝 프로젝트 절차(4) - 머신러닝 알고리즘을 위한 데이터 준비
5. 머신러닝 프로젝트 절차(5) - 모델 훈련 및 검증
7. 머신러닝 프로젝트 절차(7) - 시스템 론칭8. 머신러닝 프로젝트 절차(8) - 시스템 론칭
데이터 필드 별 요약 정보를 보며 대략적인 데이터 구조를 살펴본 후 적절한 샘플링 방식으로 데이터 샘플링한다.
이후 테스트 세트 생성을 여러 번 반복하면서 전체 데이터 셋을 다 보지 않도록 전체 데이터를 훈련 세트와 테스트 세트로 나눈다.
1. 데이터 구조 살펴보기
- df.head()
- df.info()
- df[범주형/명목형 특성].value_counts()
- df[연속형 특성].describe() # Null 값 제외한 데이터에 대한 요약정보
- df[숫자형 특성].hits(bins=50, figsize=(20,15)) # 숫자형 특성을 히스토그램으로 보기
히스토그램 통해 특성간의 스케일 조정 여부 그리고 데이터 분포를 파악한다.
히스토그램의 끝이 두껍고 가운데에서 오른쪽으로 더 멀리 뻗어 있는 형태의 경우, 일부 머신러닝 알고리즘에서 패턴을 찾기 어렵게 만들기에 종 모양으로 데이터 변형해준다.
※ 데이터 변형
회귀 모델 구현 시, 독립 변수나 종속 변수가 한 쪽으로 심하게 치우친 경우(왜도) 또는독립 변수와 종속 변수 간의 관계가 곱셉, 나눗셈으로 연결된 경우(비선형 관계) 변수에 로그 또는 제곱급 변환하면 회귀 성능이 올라갈 수 있다.
2. 데이터 샘플링
데이터 구조를 살펴본 후, 그에 적합한 샘플링 방식을 고려해야 한다.
무작위 샘플링
데이터 셋이 특성수에 비해 충분히 크다면 일반적으로 괜찮지만, 그렇지 않다면 샘플링 편향이 생길 수 있다.
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(df, test_size=0.2, random_state=42)
계층적 샘플링
테스트 세트가 전체 데이터를 대표하도록 계층 별로 올바른 수의 샘플 추출한다.
이때 계층 별로 충분한 수의 데이터 존재해야 한다. 즉 너무 많은 계층으로 나누면 안되고 각 계층이 충분히 커야 한다.
# 연속형 변수에 대해 구간을 나눠 명목형 변수 생성
df['incom_cat'] = pd.cut(df['median_income'], bins=[0.0,1.5,3.0,4.5,6,np.inf], labels=[1,2,3,4,5])
# 계층적 샘플링
st_train, st_test = train_test_split(df, test_size=0.2, random_state=42, stratify=df['incom_cat'])
과소표본추출
데이터 개수가 충분하다면, 다수의 데이터에 해당하는 클래스에서 과소표본추출을 해서 모델링할 때 0과 1의 데이터 개수에 균형을 맞출 수 있다.
과소표본추출의 기본 아이디어는 다수의 클래스에 속한 데이터들 중 중복된 레코드들이 많을 것이라는 사실에서 출발한다.
작지만 더 균형 잡힌 데이터는 모델 성능에 좋은 영향을 주게 되고, 데이터를 준비하는 과정이나 모델을 검증하는 과정이 좀 더 수월하게 된다.
※그렇다면 어느 정도의 데이터를 충분하다고 할 수 있을까?
일반적으로 소수 클래스의 데이터가 수만 개 정도 있으면 충분하다고 할 수 있다.
물론 1과 0을 분리하기 쉽다면 더 적은 데이터로도 충분할 수 있다.
과잉표본추출
과소표본 방식의 약점은 일부 데이터가 버려지기 때문에 모든 정보를 활용하지 못 한다는 점이다. 상대적으로 작은 데이터 집합에서 레코드가 몇 백, 몇 천개라면, 다수 클래스에 대한 과소표본추출은 유용한 정보까지 버리게 되는 결과를 초래할 수 있다.이럴 경우, 복원 추출 방식으로 희귀 클래스의 데이터를 과잉표본추출(Up-Sampling) 해야 한다.
데이터 생성
클래스가 1인 데이터를 모두 사용해도 그 개수가 너무 적을 때는 희귀한 데이터에 부트스트랩을 사용하거나 기존의 데이터와 유사한 합성 데이터를 만들기 위해 SMOTE 를 사용한다.
부트스트랩을 통한 업샘플링 방식의 변형으로 기존에 존재하는 데이터를 살짝 바꿔 새로운 레코드를 만드는 데이터 생성 방식이다. 이 방법에는 데이터 개수가 제한적이라 알고리즘을 통해 분류 규칙을 세우기에는 정보가 충분하지 않다는 직관이 바탕에 깔려 있다.
SMOTE 알고리즘은 업샘플링된 레코드와 비슷한 레코드를 찾고, 원래 레코드와 이웃 레코드의 랜덤 가중평균으로 새로운 합성 레코드를 만든다. 여기에 대해 각각의 예측 변수에 대해 개별적으로 가중치를 생성한다. 새로 합성된 업샘플링된 레코드의 개수는 데이터의 균형을 맞추기 위해 필요한 업샘플링 비율에 따라 달라진다.
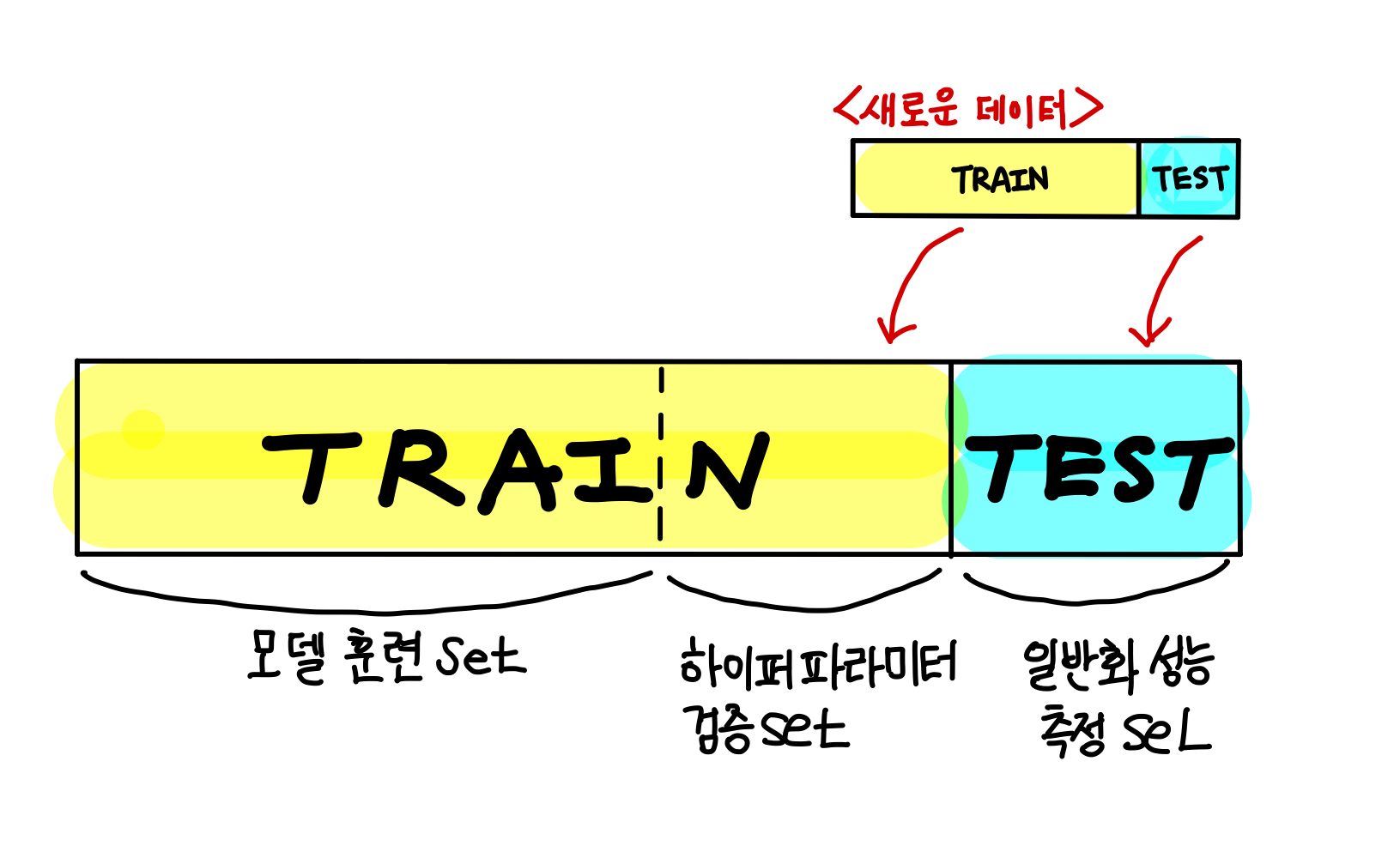
3. 테스트 세트 생성
본격적인 데이터 분석에 앞서, 테스트 세트는 따로 떼어 놓고 훈련 세트에 대해서만 데이터 분석 및 모델 훈련을 진행한다.
새로운 데이터가 업데이트될 경우, 기존 훈련 데이터가 테스트 세트가 되지 않도록 한다.
새로운 데이터도 동일한 비율로 훈련 세트와 테스트 세트를 나누어 구성한다.
'Machine Learning > 1. 머신러닝 프로젝트 절차' 카테고리의 다른 글
| [개요] 머신러닝 프로젝트 절차(4) - 머신러닝 알고리즘을 위한 데이터 준비 (0) | 2021.08.12 |
|---|---|
| [개요] 머신러닝 프로젝트 절차(3) - 데이터 이해를 위한 탐색 ... 수정중 (0) | 2021.08.12 |
| [개요] 머신러닝 프로젝트 절차(1) - 큰 그림 보기 (0) | 2021.08.12 |
| [개요] 머신러닝의 주요 도전 과제 (0) | 2021.08.12 |
| [개요] 머신러닝 시스템의 종류 (0) | 2021.08.12 |

